一探究竟线程池
线程是操作系统的资源,频繁的线程创建和销毁势必会影响并发的吞吐量。java 5引入了线程池实现了线程的复用,很好的解决了线程创建和销毁的问题。今天我们就来看下这个池子中究竟有什么
什么是线程池
类似于数据库的连接池,线程池里面保存的是线程而不是数据库连接。在线程池中,会有一个或多个可用的线程。当需要使用线程时,就可以从池子中随便取一个可用的空闲线程。当你完成工作时,不必关闭线程,而是把线程归还到线程池中,方便后续的线程需要。
线程池具有以下 3 点优势:
- 降低资源消耗,重复利用已经创建的线程,避免线程创建与销毁带来的资源消耗
- 提高响应速度,接收任务时,可以通过线程池直接获取线程,避免了创建线程带来的时间消耗
- 便于管理线程,统一管理和分配线程,避免无限制创建线程,另外可以引入线程监控机制
线程池的 5 种状态:
private static final int RUNNING = -1 << COUNT_BITS; // 111 0 0000 0000 0000 0000 0000 0000 0000
private static final int SHUTDOWN = 0 << COUNT_BITS; // 000 0 0000 0000 0000 0000 0000 0000 0000
private static final int STOP = 1 << COUNT_BITS; // 001 0 0000 0000 0000 0000 0000 0000 0000
private static final int TIDYING = 2 << COUNT_BITS; // 010 0 0000 0000 0000 0000 0000 0000 0000
private static final int TERMINATED = 3 << COUNT_BITS; // 011 0 0000 0000 0000 0000 0000 0000 0000
每个状态的含义如下:
RUNNING:接收新任务,并处理队列中的任务SHUTDOWN:不接收新任务,仅处理队列中的任务STOP:不接收新任务,不处理队列中的任务,中断正在执行的任务TIDYING:所有任务已经执行完毕,并且工作线程为 0,转换到 TIDYING 状态后将执行 Hook 方法ThreadPoolExecutor#terminatedTERMINATED:ThreadPoolExecutor#terminated方法执行完毕,该状态表示线程池彻底终止

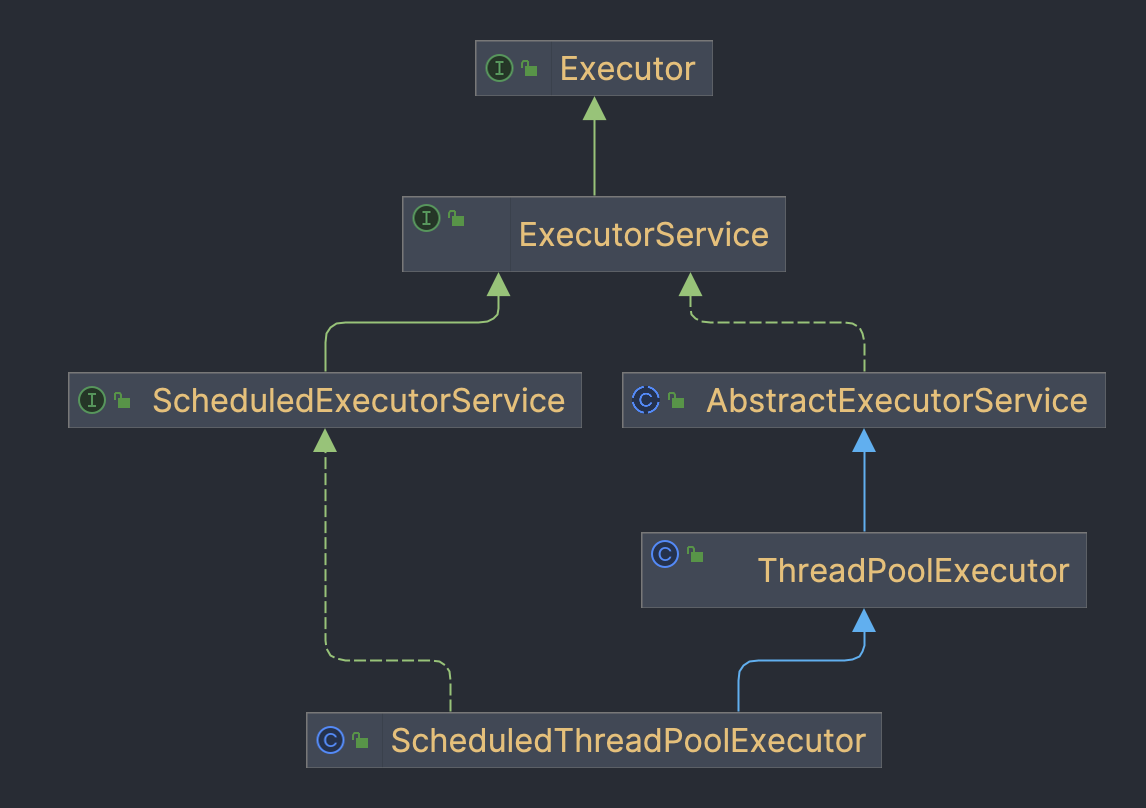
JDK的包java.util.concurrent中涵盖了Executor的框架,其中ThreadPoolExecutor是线程池,它管理着线程以为接收提交线程的任务。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
corePoolSize: 保留在池中的线程数,即使它们处于空闲状态,除非是设置了allowCoreThreadTimeOutmaximumPoolSize: 池中允许的最大线程数keepAliveTime: 当线程池线程数量超过corePoolSize时,多余的空闲线程的存活时间。 即超过corePoolSize的空闲线程,在多长时间内,会被销毀unit:keepAliveTime的时间单位workQueue: 用于在执行任务之前保存任务的队列。该队列将仅保存由execute方法提交的Runnable任务threadFactory: 线程工厂,用于创建线程handler: 拒绝策略。没有空闲线程,而且任务队列也满了。当再有新的任务添加进来,执行的拒绝策略。默认是抛出异常
线程池一般都是由Executors这个工厂类来创建,它提供了各种类型的线程池:
public static ExecutorService newFixedThreadPool(int nThreads)
public static ExecutorService newSingleThreadExecutor()
public static ExecutorService newCachedThreadPool()
public static ScheduledExecutorService newSingleThreadScheduledExecutor()
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
newFixedThreadPool: 返回一个固定数量的线程池。当有任务提交时,池中若有空闲的线程,那么立即执行。否则会把任务存放到一个任务队列中,等待有线程空闲时,便处理在任务队列中的任务。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
newSingleThreadExecutor: 返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待有线程空闲,按先入先出的顺序执行队列中的任务。
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
newCachedThreadPool: 返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务(这样可能会导致系统产生大量的线程)。所有线程在当前任务执行完毕后,将返回线程池进行复用。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
下面给出一个实例
public class CachedThreadPoolMain {
public static void main(String[] args) throws InterruptedException {
var executorService = Executors.newCachedThreadPool();
System.out.println(executorService);
for (int i = 0; i < 2; i++) {
executorService.execute(() -> {
sleep(1);
System.out.println(Thread.currentThread().getName());
});
}
System.out.println(executorService);
sleep(2);
System.out.println(executorService);
executorService.shutdown();
}
private static void sleep(int seconds) {
try {
TimeUnit.SECONDS.sleep(seconds);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
输出结果如下:
java.util.concurrent.ThreadPoolExecutor@a09ee92[Running, pool size = 0, active threads = 0, queued tasks = 0, completed tasks = 0]
java.util.concurrent.ThreadPoolExecutor@a09ee92[Running, pool size = 2, active threads = 2, queued tasks = 0, completed tasks = 0]
pool-1-thread-2
pool-1-thread-1
java.util.concurrent.ThreadPoolExecutor@a09ee92[Running, pool size = 2, active threads = 0, queued tasks = 0, completed tasks = 2]
newSingleThreadScheduledExecutor: 返回一个ScheduledExecutorService对象,线程池大小是1。
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
newScheduledThreadPool: 该方法也返回一个ScheduledExecutorService对象,但该线程池可以指定线程数量。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
下面我们就以简单的例子加以说明:
public class FixedThreadPool {
public static void main(String[] args) {
var executorService = Executors.newFixedThreadPool(4);
for (int i = 0; i < 8; i++) {
executorService.submit(new Task(i));
}
executorService.shutdown();
}
static class Task implements Runnable {
private final int index;
public Task(int index) {
this.index = index;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + ", id = %d, time = %s".formatted(index, LocalDateTime.now()));
try {
TimeUnit.SECONDS.sleep(index + 1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
输出结果是:
pool-1-thread-3, id = 2, time = 2023-08-23T17:23:27.079117
pool-1-thread-2, id = 1, time = 2023-08-23T17:23:27.079033
pool-1-thread-4, id = 3, time = 2023-08-23T17:23:27.079035
pool-1-thread-1, id = 0, time = 2023-08-23T17:23:27.079031
pool-1-thread-1, id = 4, time = 2023-08-23T17:23:28.105052
pool-1-thread-2, id = 5, time = 2023-08-23T17:23:29.104030
pool-1-thread-3, id = 6, time = 2023-08-23T17:23:30.104577
pool-1-thread-4, id = 7, time = 2023-08-23T17:23:31.104777
程序中创建一个固定数量为4的线程池,同时创建了8个任务。任务中打印出index值,随后睡眠index + 1秒。从输出结果上看,前四个任务立马得到了执行,线程的顺序是3241,处理的id顺序是2130。根据任务中睡眠时间(也可以说是执行时间)是index递增,所以线程执行完的顺序大概率是1234,即被释放的线程陆续处理接下来的4个任务。
计时任务
scheduleWithFixedDelay: 创建并执行一个周期性任务。任务开始于初始延时时间,period是下一人任务相对于上一个任务的结束时间来的。scheduleAtFixedRate: 创建一个周期性任务。任务开始于给定的初始延时时间,period是下一人任务相对于上一个任务的开始时间来的(要保证上一个任务完成才进行下一个任务)。
由于线程池支持定时的任务,下面我们就举一个计时任务的例子:
public class ScheduledThreadPool {
public static void main(String[] args) throws InterruptedException {
var scheduledExecutorService = Executors.newScheduledThreadPool(6);
scheduledExecutorService.scheduleWithFixedDelay(new Task(), 1, 3, TimeUnit.SECONDS);
System.out.println(Thread.currentThread().getName() + ", time: " + LocalDateTime.now());
TimeUnit.SECONDS.sleep(15);
scheduledExecutorService.shutdown();
System.out.println(Thread.currentThread().getName() + ", time: " + LocalDateTime.now());
}
static class Task implements Runnable {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + ", time: " + LocalDateTime.now());
try {
TimeUnit.SECONDS.sleep(4);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
输出结果是:
main, time: 2023-08-25T11:25:14.281678
pool-1-thread-1, time: 2023-08-25T11:25:15.267234
pool-1-thread-1, time: 2023-08-25T11:25:22.274503
pool-1-thread-2, time: 2023-08-25T11:25:29.279348
main, time: 2023-08-25T11:25:29.296934
上述第5行代码将scheduleWithFixedDelay方法改成scheduleAtFixedRate,那么输出结果:
main, time: 2023-08-25T11:25:51.540083
pool-1-thread-1, time: 2023-08-25T11:25:52.530656
pool-1-thread-1, time: 2023-08-25T11:25:56.534709
pool-1-thread-2, time: 2023-08-25T11:26:00.535428
pool-1-thread-1, time: 2023-08-25T11:26:04.538647
main, time: 2023-08-25T11:26:06.552026
Tips
如果某个任务遇到异常,那么后续的所有子任务都会停止调度。
Jdk的线程池
线程池的原理
while (task != null || (task = getTask()) != null)
首先从Worker里面拿firstTask,如果返回null。那么就从Queue里面取任务。
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
if (runStateAtLeast(c, SHUTDOWN)
&& (runStateAtLeast(c, STOP) || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
如果说wc > corePoolSize,那么timed就为true。所以从queue里面poll任务,keepAliveTime还没有拿到任务。则说明,线程池的空闲线程已经等了keepAliveTime时间。这时,
keepAliveTime的作用,源码?当线程池线程数量超过corePoolSize时,多余的空闲线程的存活时间。 即超过corePoolSize的空闲线程,在多长时间内,会被销毀
拒绝策略
线程池中没有空闲线程,而且任务队列也满了。当再有新的任务添加进来,就会执行线程池的拒绝策略。JDK提供了以下四种拒绝策略,当然我们也可以自定义拒绝策略,实现RejectedExecutionHandler接口并重写rejectedExecution方法。通常情况的处理方法可能就是,先把这些重要任务保存起来(可能是数据库,也可以是redis这种)并做好日志,后续pull出来再做处理。
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
下面我们就来展开看下JDK中提供给我们的使用的四种拒绝策略。
AbortPolicy: 抛出异常
public static class AbortPolicy implements RejectedExecutionHandler {
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() + " rejected from " + e.toString());
}
}
DiscardPolicy: 什么都不做,那就是任务废弃了
public static class DiscardPolicy implements RejectedExecutionHandler {
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
DiscardOldestPolicy: 废弃任务等待队列中的头部任务,也就是最老的那个任务
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
CallerRunsPolicy: 在调用者线程中来执行新的任务
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
线程池的拓展
ThreadFactory
默认的线程工厂是DefaultThreadFactory,它的构造方法和创建线程的方法:
DefaultThreadFactory() {
@SuppressWarnings("removal")
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() : Thread.currentThread().getThreadGroup();
namePrefix = "pool-" + poolNumber.getAndIncrement() +"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r, namePrefix + threadNumber.getAndIncrement(), 0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
线程数量的配置
如果线程池中的线程数量过多,最终它们会竞争稀缺的处理器和系统资源,浪费大量的时间在上下文切换。如果线程池中的线程数目过少,那么处理器的一些核就无法得到充分的利用。

一般我们的程序都会分为以下几种类型,CPU密集型(计算密集型)、IO密集型、混合型,针对每种类型的程序我们有不同的配置方案。
CPU密集型
CPU密集型也就是计算密集型,常常指算法复杂的程序,需要进行大量的逻辑处理与计算,CPU在此期间是一直在工作的。
在这种情况下CPU的利用率会非常高,我们的最大核心线程数设置为CPU的核心数即可。
最大线程数 = CPU核心数 + 1
核心线程数 = 最大线程数 * 20%
IO密集型
IO密集型是指我们程序更多的工作是在通过磁盘、内存或者是网络读取数据,在IO期间我们线程是阻塞的,这期间CPU其实也是空闲的,这样我们的操作系统就可以切换其他线程来使用CPU资源。
通常在进行接口远程调用,数据库数据获取,缓冲数据获取都属于IO操作。
这时我们线程数可以通过以下公式进行计算:最大线程数 = CPU核心数 / (1 - 阻塞占百分比)。
我们很好理解比如在某个请求中,请求时长为10秒,调用IO时间为8秒,这时我们阻塞占百分比就是80%,有效利用CPU占比就是20%,假设是八核CPU,我们线程数就是8 / (1 - 80%) = 8 / 0.2 = 40 个。
也就是说 我们八核CPU在上述情况中,可满负荷运行40个线程。这时我们可将最大线程数调整为40,在系统进行IO操作时会去处理其他线程。
通过情况下,我们会设置:
最大线程数 = CPU核心数 * 2
核心线程数 = 最大线程数 * 20%
混合型
混合型程序,指既包含CPU密集型,又包含IO密集型。
对于此类程序,我们可以将任务划分成CPU密集型任务与IO密集型任务,分别针对这两种任务使用不同的线程池去处理。这样我们就可以针对这两种情况对线程池配置不同的参数。
FAQ
总结
参考资料
还有一种线程池叫做ForkJoinPool,具体参考:fork-join-pool