Java小技巧
如何编写更健壮更好的java代码?这里面整理收集一些在java开发过程中我们需要注意的一些点或者说是技巧,从而提高代码的质量以及我们的工作效率。
Springboot
Ignore Null Fields with Jackson
Springboot中默认序列化Json的框架就是jackson了,这里面介绍在Springboot项目中如何忽略null字段
- 全局
springboot配置和java代码都可以实现全局忽略null的功能
spring:
jackson:
default-property-inclusion: non_null
var mapper = new ObjectMapper();
mapper.setSerializationInclusion(Include.NON_NULL);
- 类级别
@JsonInclude(Include.NON_NULL)
public class Person { ... }
- 字段级别
public class MyPersonDto {
private String name;
@JsonInclude(Include.NON_NULL)
private String address;
}
@RequestHeader的name忽略大小写
HTTP中header的name是忽略大小写,这个在RFC 2616规范中定义。
具体在SpringBoot和Tomcat的实现,后续简单补上。
全局异常处理
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(ProductNotFoundException.class)
public ResponseEntity<String> handleProductNotFound(ProductNotFoundException ex) {
return ResponseEntity.status(HttpStatus.NOT_FOUND).body(ex.getMessage());
}
}
List对象的属性配置
一般来说,如果属性是一个List的话,会有一层包装。比如下面的例子:
@Component
@ConfigurationProperties(prefix = "app.module")
public class DatabaseProperties {
private List<DatabaseProperty> databases;
}
@Service
@RequiredArgsConstructor
public class DatabaseAppService {
private final DatabaseProperties databaseProperties;
}
而如果我们想去掉DatabaseProperties,直接对List进行Bean的注入呢?下面便是答案
app:
module:
database:
- environment: dev
suffix: -postgres-v1
- environment: test
suffix: -postgres-v2
public record DatabaseProperty(String environment, String suffix) {}
@Configuration
public class DatabaseConfiguration {
@Bean
@ConfigurationProperties(prefix = "app.module.database")
public List<DatabaseProperty> databasePropertyList() {
return new ArrayList<>();
}
}
@Service
@RequiredArgsConstructor
public class DatabaseAppService {
private final List<DatabaseProperty> databaseProperties;
}
Tips
对比上述两种方式,下面列举下优缺点:
第一种:有外层类DatabaseProperties做包装,因此有加额外逻辑的能力。但在引用的地方,会相对多了一个getDatabases操作
第二种:在使用的地方,是直接引用List属性的,更为简单直接
EnableXXX等注解的位置
在一些项目上,看到类似于下方的代码把注解集中放在项目的入口类上面,如下代码所示:
@EnableDiscoveryClient
@EnableFeignClients
@EnableRetry
@EnableAsync(proxyTargetClass = true)
@EnableScheduling
@EnableSchedulerLock(defaultLockAtMostFor = "PT30M")
public class LoveApplication {
public static void main(String[] args) {
SpringApplication.run(LoveApplication.class, args);
}
}
上面的一些EnableRetry、EnableAsync等之类的注解是统一放在LoveApplication,还是单独放在一个Configuration的类中,然后里面还包含自定义的配置。哪种方式会比较好呢?
Docker
docker远程Debug
- 使用docker部署项目
# 9094: 应用端口, 5005: 远程debug的端口,需要远程的服务器防火墙打开此接口
docker run -d -p 9094:9094 -p 5005:5005 \
-e "JAVA_TOOL_OPTIONS=\"-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5005\"" \
--name demo_app demo_app:0.0.1-SNAPSHOT
- 检查远程接口是否打开
nc -vz 47.111.12.18 5005
输出的日志中带有Connection to .... successed就代表远程的5005接口是可以连通的。
- intellj配置
Remote Jvm Debug
# import thing is the JVM arguments
-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5005
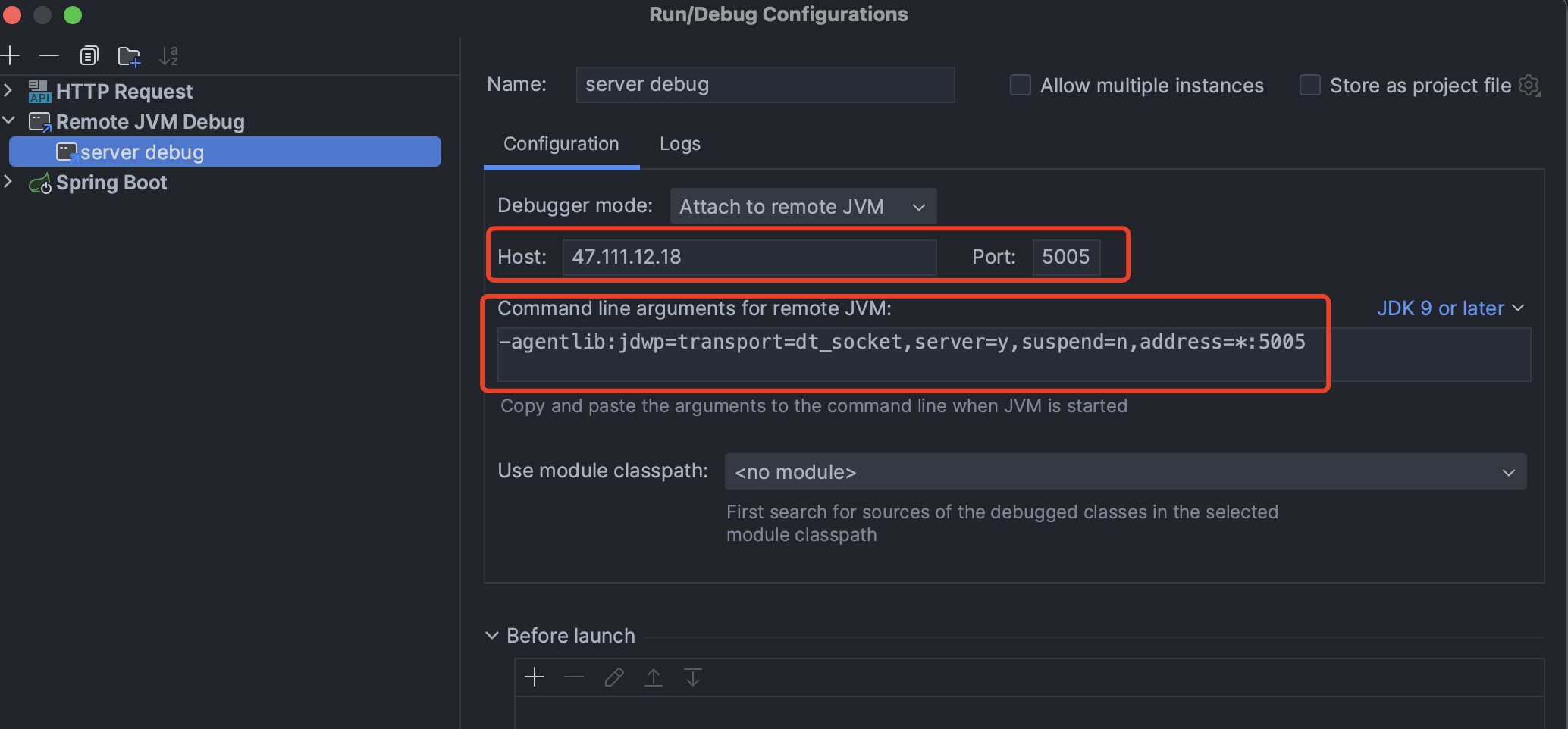
本地和远程的源代码要保持一致,要不然本地的debug会不能工作。
- 运行测试
本地代码打上断点,在idea上面点击server debug以debug模式运行。访问远程的api,就会走到本地相应的断点。
Standard
Boolean的短路评估
&&: 如果左边表达式为false,那么右边表达式不会执行||: 如果左边表达式为true,那么右边表达式不会执行
利用这个特性的话,在编写代码就可以通过变换表达式的位置或者提取方法来优化性能,比如
public boolean shouldSkip {
var hasOutput = CollectionUtils.isNotEmpty(response.getSpec().getOutputs());
var hasSecret = provider.callRemoteApi("string");
return hasSecret || hasOutput;
}
public boolean shouldSkip {
var hasOutput = CollectionUtils.isNotEmpty(response.getSpec().getOutputs());
return hasOutput || hasSecret("string");
}
private boolean hasSecret(String string) {
return provider.callRemoteApi(string);
}
总的原则就是把耗时和复杂的表达式滞后,如果表达式比较长的话,可以提取成函数。
静态方法的调用
当通过 Java 中的空引用调用静态方法时,不会引发异常并且代码会运行。
public class Main {
public static void main(String[] args) {
Greeting greeting = null;
greeting.hello(); // Hello
}
}
class Greeting {
public static void hello() {
System.out.println("Hello");
}
}
静态方法属于类而不是实例,在编译时greeting.hello()变成Greeting.hello()。调用静态方法时始终使用类名,而不是实例。
枚举类的比较
对于枚举判断相等,我们可以使用==或者equals方法
- 使用
==
boolean isEnabled = accountStatus == Status.ENABLED; // true or false
boolean isEnabled = "string" == Status.ENABLED; // compiler error
如果accountStatus为null,上述可以工作。如果accountStatus不是一个枚举,那编译报错。
- 使用
equals
将枚举常量放在左边,这样就可以避免空指针异常,但是没有类型的编译时检查。
boolean isEnabled = Status.ENABLED.equals(accountStatus); // true or false
boolean isEnabled = Status.ENABLED.equals("null") // false,正常编译
Tips
对于枚举判断相等,推荐使用==,因为它提供类型的编译时检查并且保证了null安全
Map的get方法为null的情况
Map的get方法返回结果为null是有两种情况:
- The map does not contain the provided key
- The map does contain the key but its value is null
所以说如果想要判断key在map中是否存在,建议使用contains(Object key)方法。另外Java 8中提供了getOrDefault(Object key, V defaultValue),如果相应的key对应的值是null,那么返回defaultValue。
Stream中检查存在性
Java 8中引入的Stream,方便了我们对Collection的操作。在检查Java流中是否存在时,使用anyMatch()而不是count() > 0
// Stream has 10k objects
// 2ms
result = employees.stream().anyMatch(e -> e.isActive());
// 20ms
result = employees.stream().fliter(e -> e.isActive()).count() > 0;
Tips
对比于count() > 0,使用anyMatch()更安全,性能也更好。因为anyMatch在检索过程中,如果发现有一个满足条件,就直接返回true了。而count() > 0撘配filter会检索整个Stream。
null的instanceof操作符
如果对象为null,那么instanceof运算符将返回false。
// before
if (object != null && object instanceof MyClass) {}
// after: better
if (object instanceof MyClass) {}
谨慎使用BigDecimal(double)构造
BigDecimal(double)存在精度损失风险,在精确计算或值比较的场景中可能会导致业务逻辑异常。比如下面实际存储的值就是:0.100000001490116119384765625
BigDecimal value = new BigDecimal (0.1f)
优先推荐BigDecimal(String)的构造方法或使用BigDecimal.valueOf方法,此方法内部其实执行了Double的toString方法,而Double的toString按double的实际能表达的精度对尾数进行了截断。
BigDecimal recommend1 = new BigDecimal("0.1");
BigDecimal recommend2 = BigDecimal.valueOf(0.1);
当涉及到金钱、对精度有要求的计算时,最好是使用BigDecimal,而不是使用Double或者Float。当然对比于运算速度,Bigdecimal是要慢些的。
0.1d * 0.2d; // 0.020000000000000004
BigDecimal.valueOf(0.1d).multiply(BigDecimal.valueOf(0.2d)); // 0.02
整型包装类对象之间值的比较
对于Integer.valueOf(i)在-128至127之间的赋值,Integer对象是在IntegerCache.cache产生,会复用已有对象,这个区间内的Integer值可以直接使用==进行判断。
但是这个区间之外的所有数据,都会在堆上产生,并不会复用已有对象,这是一个大坑。
Info
所有整型包装类对象之间值的比较,全部使用 equals 方法比较。
System.out.println(Integer.valueOf(12) == Integer.valueOf(12)); // true
System.out.println(new Integer(12) == new Integer(12)); // false
System.out.println(Integer.valueOf(258) == Integer.valueOf(258)); // false
System.out.println(Integer.valueOf(12).equals(Integer.valueOf(12))); // true
System.out.println(new Integer(12).equals(new Integer(12))); // true
System.out.println(Objects.equals(Integer.valueOf(258), Integer.valueOf(258))); // true
new Integer(i)这个方法在java 9已经被标记为废弃,被推荐使用Integer.valueOf方法。这个方法的代码如下:
@IntrinsicCandidate
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
@IntrinsicCandidate
public static Long valueOf(long l) {
final int offset = 128;
if (l >= -128 && l <= 127) { // will cache
return LongCache.cache[(int)l + offset];
}
return new Long(l);
}
new String和String
public class StringPool {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "hello";
String s3 = new String("hello");
System.out.println(s1 == s2); // true
System.out.println(s1 == s3); // false
}
}
String str = "hello;"这将创建一个值为hello的字符串对象。字符串字面量被存储在字符串池中,这意味着如果你创建另一个具有相同值的字符串,它将引用内存中的相同对象。这被称为字符串池技术。String str = new String("hello");这也将创建一个值为hello的字符串对象。与字符串字面量不同,使用new String()总是在堆内存中创建一个新的对象,即使字符串池中已经存在一个具有相同值的字符串。这在需要显式创建新对象的情况下可能有用,但在常规Java编程中不常见。
HashSet和LinkedHashSet的相等
public class SetEquality {
public static void main(String[] args) {
Set<String> hashSet = new HashSet<>();
hashSet.add("element");
Set<String> linkedHashSet = new LinkedHashSet<>();
linkedHashSet.add("element");
System.out.println(hashSet.equals(linkedHashSet)); // true
}
}
HashSet和LinkedHashSet相等性的比较,就算元素存储和迭代顺序不同,只要包含相同的元素就认为是相等的。主要原理是因为他们没有重写父类AbstractSet的equals方法。而在AbstractSet类中
// AbstractSet
public boolean equals(Object o) {
if (o == this) return true;
if (!(o instanceof Set)) return false;
Collection<?> c = (Collection<?>) o;
if (c.size() != size()) return false;
try {
return containsAll(c); // 只要包含的元素相同就好,顺序没关系
} catch (ClassCastException | NullPointerException unused) {
return false;
}
}
public boolean containsAll(Collection<?> c) {
for (Object e : c)
if (!contains(e)) return false;
return true;
}
String中的各种replace方法
@Test
public void stringReplace() {
replaceFirst("year = 1929. month=07, day=29, other=\\d{2}");
}
public void replaceFirst(String string) {
System.out.println(string.replaceFirst("\\d{2}", "--"));
System.out.println(string.replace("\\d{2}", "--"));
System.out.println(string.replace("29", "--"));
System.out.println(string.replaceAll("\\d{2}", "--"));
}
// year = --29. month=07, day=29, other=\d{2}
// year = 1929. month=07, day=29, other=--
// year = 19--. month=07, day=--, other=\d{2}
// year = ----. month=--, day=--, other=\d{2}
replaceFirst: 参数是正则表达式,只是替换第一次匹配成功的相应字符串replace: 参数是字符串,替换所有匹配成功的相应字符串replaceAll: 参数是正则表达式,替换所有匹配成功的相应字符串
Java8中的StringJoiner
StringJoiner stringJoiner = new StringJoiner(",", "[", "]");
stringJoiner.add("huhx");
stringJoiner.add("linux");
stringJoiner.add(null);
System.out.println(stringJoiner.toString()); // [huhx,linux,null]
StringJoiner有三个参数,分别是delimiter、prefix和suffix。StringJoiner的toStrin()实现本质上还是String类中的join静态方法。
这里面的join方法不是public的,具体为什么可以被StringJoiner类调用?我猜想是由于用上了@ForceInline注解,这里不多做解释。
@ForceInline
static String join(String prefix, String suffix, String delimiter, String[] elements, int size)
String中其实是有public的join方法的,只是不带prefix和suffix这两个参数而已。
public static String join(CharSequence delimiter, CharSequence... elements)
public static String join(CharSequence delimiter, Iterable<? extends CharSequence> elements)
Tips
需要注意的是,在StringJoiner的add方法参数是null时,会被视为null字符串。
// from StringJoiner
public StringJoiner add(CharSequence newElement) {
final String elt = String.valueOf(newElement);
......
}
// from String
public static String valueOf(Object obj) {
return (obj == null) ? "null" : obj.toString();
}
时间类的选择
Java关于时间的类数不胜数,而在Java8中又引入了LocalDate、LocalDateTime和Instant等类,更是乱花见人迷人眼,让人不知道如何选择。现在我们就给时间分个类,讲解下它们的不同以及各自的使用场景。
Date:Calendar:LocalDate和LocalDateTime:Timestamp:Instant:ZonedDateTime:
时间相关的类
Duration:Period:DateTimeFormatter:ChronoUnit:
Framework
重写@Builder中的build方法
在使用Lombok的项目中,使用了@Builder注解。有一个需求就是在build的时候,需要做额外的处理。
想要使用@Builder注解提供的builder方法,又想在build方法时有自己的逻辑。当然可以不使用Lombok的@Builder注解,自己手写Builder冗余代码,灵活性高些。
@Getter
@Builder
public class UserAddress {
private String id;
private String ciamId;
private String address;
// 在UserAddress的Builder类中,增加新的方法。最后调用build方法生成UserAddress
@SuppressWarnings("unused")
public static class UserAddressBuilder {
// 这里使用create而不是build,因为里面调用build方法。会导致无限循环调用build方法
public UserAddress create() {
if (id == null || id.isBlank()) {
this.id = ciamId != null
? "MD5 this class"
: UUID.randomUUID().toString();
}
return build();
}
}
// 以下是测试的类
public static void main(String[] args) {
UserAddress userAddress = UserAddress.builder()
.ciamId("ciam id")
.address("address")
.create();
System.out.println(userAddress.getId()); // MD5 this class
}
}
Lombok的最小原则
在Spring的项目中,Lombok已是遍地开花,运用广泛。项目中充斥着各种各样的Lombok注解,在运用这个工具的同时,我们得按需精准地加注解。下面列举一些场景
- Value object
@Value
public class SimpleMoney {
String currency;
Long amount;
}
- Enum class
@Getter
@AllArgsConstructor
public enum PayStatus {
PENDING(0, "进行中"), FAILED(100, "交易失败"), SUCCESS(200, "交易成功");
private final int code;
private final String content;
}
- Configuration class
@Data
@Configuration
@ConfigurationProperties(prefix = "oss")
public class OssProperties {
private String region;
private String host;
}
最小其实@Getter和@Setter就可以,但是@Data提供@ToString、@EqualsAndHashCode等能力,方便日志以及比较。
- Request class
@Getter
@Builder
public class CreateDatabaseRequest {
private String name;
private String environment;
}
- Response class
@Getter
@Builder
public class CreateDatabaseResponse {
private Long id;
private String name;
}
- Entity class
@Data
@Entity
@Table(name = "tool")
public class Tool {
@Id
private Integer id;
private LocalDateTime createTime;
}
- Extended Entity class
@Setter
@Getter
@MappedSuperclass
@NoArgsConstructor
@SuperBuilder
public abstract class BaseEntity {
@Id
private Long id;
}
@Entity
@Getter
@NoArgsConstructor
@SuperBuilder
@Table(name = "baby")
public class Baby extends BaseEntity {
private String name;
}
Question: Java 14加入了Record的新特性,那么对于Lombok的使用是否还有必要?
Answer: 如果只是需要简单的不可变数据模型,那么Record可能已经足够了。但如果你需要更多的功能或者需要与较旧的Java版本兼容,那么Lombok仍然具有使用的必要性。
Tips
上述场景可以被Record类替代使用的有以下几种:
Configuration classValue object
Swagger与业务分离
在Spring的web项目中,Swagger经常被作为生成Restful接口文档的Web 服务。在Controller中既要定义Restful也要定义Swagger,这样会让代码变得杂乱不堪。
这个时候我们可以把Restful接口的定义与Swagger文档的定义给隔离开,职责得以分离,阅读代码也赏心悦目。
@RequestMapping("v1/orders")
public class OrderController implements OrderApi {
@Override
@GetMapping("/{orderNo}/payment")
public ApiResponse<GetPaymentResponse> get(@PathVariable String orderNo) {
GetPaymentResponse result = paymentService.get(orderNo);
return ApiResponse.success(result);
}
}
@Api(tags = "Payment管理")
public interface PaymentApi {
@ApiOperation(value = "根据业务订单号获取支付结果")
ApiResponse<GetPaymentResponse> get(@Parameter(description = "业务订单号", example = "1234568977") String orderNo);
}
当然Swagger应该有更为彻底的文档与业务分离的实现,使用基于配置的文档生成工具,这个属于后话,后面有机会再做讨论。
Warning
PaymentApi类中Swagger的注解还是存在于Java的代码中,具有一定的耦合性。
理论上说文档跟着代码走,可以更好的理解API的行为,不至于代码做了修改文档却没变动。