Java正则表达式
正则基本上算是每个开发语言的标配,其重要性不言而谕。之所以正则经久不衰,主要在于它在文字处理方面展现出恐怖而全面的能力。今天我们就来了解下这个文字处理神器:正则表达式。
什么是正则表达式
正则表达式是用字符串描述的一个匹配规则,它们可用于搜索、编辑或操作文本和数据。正则的实现百家争鸣,各个语言实现的版本具有差异化,常见的有grep、Perl、Tcl、Python、PHP和awk,但是不用过于担心基本上是大同小异。
我们今天主要说的是java中的正则,它的风格算是跟Perl走得最为接近。java是面向对象的,表达正则肯定是用对象了。那么会有那些对象呢?
关于正则,java是有一个叫java.util.regex包的。它里面涵盖了正则的所有要求,其中最为重要的莫过于:Pattern、Matcher和PatternSyntaxException
Pattern: 正则表达式的编译表示,无构造函数。由带参数的静态函数创建
public static Pattern compile(String regex) {
return new Pattern(regex, 0);
}
public static Pattern compile(String regex, int flags) {
return new Pattern(regex, flags);
}
构造函数有两个参数,regex表示要编译的表达式,flag表示匹配规则中的标志位(这个在后面会讲到)。
Matcher: 是解释模式并对输入字符串执行匹配操作的引擎,也是无构造函数,由Pattern对象中的matcher方法生成
var pattern = Pattern.compile("ab.");
var matcher = pattern.matcher("abc");
System.out.println(matcher.matches()); // true
PatternSyntaxException: 是unchecked的异常,表示正则表达式模式中存在语法错误
var pattern = Pattern.compile("[]"); // java.util.regex.PatternSyntaxException: Unclosed character class near index 1
为了展开后面的学习,这里写一个正则表达式的程序用于测试:接收控制台的正则表达式和字符串输入,然后打印出匹配的字符串以及相应的index
package com.huhx.regex;
import java.util.regex.Pattern;
public class RegexTestHarness {
public static void main(String[] args) {
var console = System.console();
if (console == null) {
System.err.println("No console.");
System.exit(1);
}
while (true) {
var pattern = Pattern.compile(console.readLine("%nEnter your regex: "));
var string = console.readLine("Enter input string to search: ");
var matcher = pattern.matcher(string);
boolean found = false;
while (matcher.find()) {
console.format("I found the text" +
" \"%s\" starting at " +
"index %d and ending at index %d.%n",
matcher.group(),
matcher.start(),
matcher.end());
found = true;
}
if (!found) {
console.format("No match found.%n");
}
}
}
}
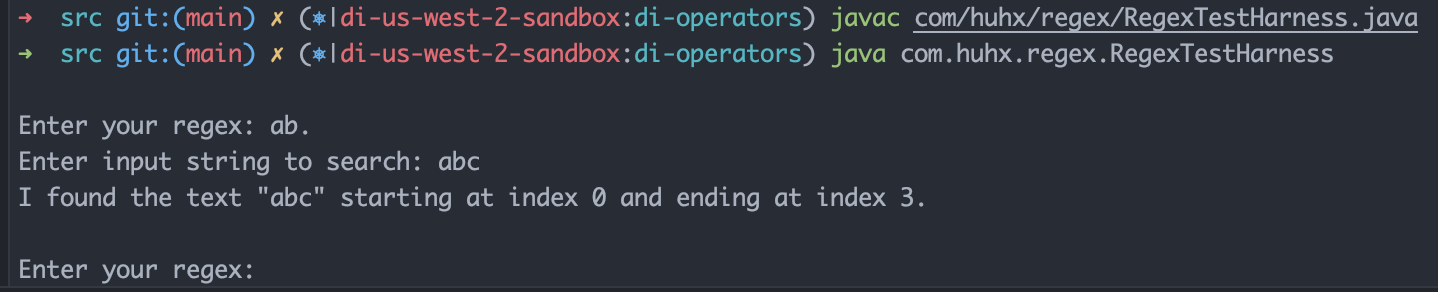
在src目录下面,使用以下命令行编译和运行
javac com/huhx/regex/RegexTestHarness.java
java com.huhx.regex.RegexTestHarness
字符串文字
正则最基本形式是字符串文字的匹配,比如说正则表达式为foo并且输入字符串为foo,那就是匹配了。
Enter your regex: abc
Enter input string to search: abcabcabc
I found the text "abc" starting at index 0 and ending at index 3.
I found the text "abc" starting at index 3 and ending at index 6.
I found the text "abc" starting at index 6 and ending at index 9.
按照约定,范围包含起始索引但不包含结束索引。所以第一个abc的匹配index为[0,3)。
其中需要注意的是,正则表达式中定义了一些元字符。这些字符有着特殊的含义,比如说.表示任意字符
Enter your regex: ab.
Enter input string to search: abd
I found the text "abd" starting at index 0 and ending at index 3.
那么java中都有哪些类似的元字符呢?而如果我就是想把元字符当成普通字符来匹配又该如何是好呢?
元字符有<([{\^-=$!|]})?*+.>,而强制将元字符视为普通字符的方法有以下两种:
- 元字符之前加一个反斜杠
\ - 将元字符括在
\Q(开始引用)和\E(结束引用)内
Enter your regex: ab\.
Enter input string to search: abd
No match found.
Enter your regex: ab\.
Enter input string to search: ab.
I found the text "ab." starting at index 0 and ending at index 3.
Enter your regex: ab\Q.\E
Enter input string to search: abd
No match found.
Enter your regex: ab\Q.\E
Enter input string to search: ab.
I found the text "ab." starting at index 0 and ending at index 3.
Enter your regex: \Qab.\E
Enter input string to search: ab.
I found the text "ab." starting at index 0 and ending at index 3.
Tips
\Q和\E可以放置在表达式内的任何位置,前提是\Q在前面。
方括号内字符
| 正则表达式构造 | 描述说明 |
|---|---|
[abc] | a, b, or c (simple class) |
[^abc] | Any character except a, b, or c (negation) |
[a-zA-Z] | a through z, or A through Z, inclusive (range) |
[a-d[m-p]] | a through d, or m through p: [a-dm-p] (union) |
[a-z&&[def]] | d, e, or f (intersection) |
[a-z&&[^bc]] | a through z, except for b and c: [ad-z] (subtraction) |
[a-z&&[^m-p]] | a through z, and not m through p: [a-lq-z] (subtraction) |
方括号里面的字符是或关系的,比如说[ab]就是a或b都可以匹配。-表示范围(包含首尾字符),比如[1-9]就是匹配的数字在1到9(包含1和9这两个字符)之间。而^表示否定关系的,比如[^ab]就是除了a和b之外所有的字符。而&&表示且的关系,[ab&&bc]就是ab和bc的交集,也就是b。
下面给出一些例子:
[0-4[6-8]]: 0, 1, 2, 3, 4, 6, 7 and 8[0-9&&[345]]: 3, 4, and 5[2-8&&[4-6]]: 4, 5, and 6[0-9&&[^345]]: 3, 4, and 5
预定义字符
| 正则表达式构造 | 描述说明 |
|---|---|
. | Any character (may or may not match line terminators) |
\d | A digit: [0-9] |
\D | A non-digit: [^0-9] |
\s | A whitespace character: [ \t\n\x0B\f\r] |
\S | A non-whitespace character: [^\s] |
\w | A word character: [a-zA-Z_0-9] |
\W | A non-word character: [^\w] |
预定义字符比较简洁,尽可能使用它,可以使您的代码更易于阅读并消除格式错误的字符类引入的错误。
以反斜杠\开头的结构称为转义结构。当我们使用\d之类的,在字符串文字中使用转义构造,则必须在反斜杠前面加上另一个反斜杠才能编译字符串。至于原因,参考:String正则加反斜杠
// 编译报错:Illegal escape character in string literal
var pattern = Pattern.compile("\d");
// 正常编译:表示匹配一个数字
var pattern = Pattern.compile("\\d");
匹配次数量词
很多情况下,我们会有对某些字符多次匹配的需求,比方说1212或者大大方方这类的叠词。这根本就难不倒正则,它提供了丰富的功能去满足这些字符多次匹配的需求。
| Greedy | Reluctant | Possessive | Meaning |
|---|---|---|---|
X? | X?? | X?+ | X, once or not at all |
X* | X*? | X*+ | X, zero or more times |
X+ | X+? | X++ | X, one or more times |
X{n} | X{n}? | X{n}+ | X, exactly n times |
X{n,} | X{n,}? | X{n,}+ | X, at least n times |
X{n,m} | X{n,m}? | X{n,m}+ | X, at least n but not more than m times |
乍一看,X?, X??和X?+做完全相同的事情,因为它们都表示匹配X一次或根本不匹配。然而事实却没那么简单。
Enter your regex: .*foo
Enter input string to search: xfooxxxxxxfoo
I found the text "xfooxxxxxxfoo" starting at index 0 and ending at index 13.
Enter your regex: .*?foo
Enter input string to search: xfooxxxxxxfoo
I found the text "xfoo" starting at index 0 and ending at index 4.
I found the text "xxxxxxfoo" starting at index 4 and ending at index 13.
Enter your regex: .*+foo
Enter input string to search: xfooxxxxxxfoo
No match found.
捕获组
捕获组是将多个字符视为一个单元的一种方法。它们是通过将要分组的字符放在一组括号内来创建的。
组的编号
在java中,捕获组通过从左到右计算其左括号来进行编号。
例如,在表达式 ((A)(B(C)))中,有四个这样的组:
((A)(B(C)))(A)(B(C))(C)
Jdk还提供了组数的查询,调用Matcher对象的groupCount方法就可以。
var matcher = Pattern.compile("((A)(B(C)))").matcher("aaa");
System.out.println(matcher.groupCount());
还有一个特殊的组,是group 0。因为它始终代表整个表达式,所以没有包含在groupCount方法的返回当中。以下是groupCount的源码:
public int groupCount() {
return parentPattern.capturingGroupCount - 1;
}
了解组的编号至关重要,后续就可以根据此编号来取某个组的匹配内容。Matcher类提供了一些以下有用的方法:
public int start(int group)
public int end(int group)
public String group(int group)
反向引用
与捕获组匹配的输入字符串部分保存在内存中,以便以后通过反向引用调用。反向引用在正则表达式中指定为反斜杠\,后跟一个指示要调用的组编号的数字n。例如表达式 (\d\d)定义一个与一行中的两个数字匹配的捕获组,稍后可以通过反向引用\1在表达式中调用该捕获组。
如果想匹配类似于2323这种两个数字,后面跟相同的两个数字。正则表达式可以写成:(\d\d)\1
Enter your regex: (\d\d)\1
Enter input string to search: 2323
I found the text "2323" starting at index 0 and ending at index 4.
Enter your regex: (\d\d)\1
Enter input string to search: 2324
No match found.
边界匹配
到目前为止,我们只关心是否在特定输入字符串中的某个位置找到匹配项。我们从不关心比赛发生在字符串的哪个位置。
您可以通过使用边界匹配器指定此类信息来使模式匹配更加精确。例如,也许您有兴趣查找某个特定单词,但前提是该单词出现在行首或行尾。或者您可能想知道匹配是否发生在单词边界上,或者发生在上一个匹配的末尾。
| Boundary Construct | Description |
|---|---|
^ | The beginning of a line |
$ | The end of a line |
\b | A word boundary |
\B | A non-word boundary |
\A | The beginning of the input |
\G | The end of the previous match |
\Z | The end of the input but for the final terminator, if any |
\z | The end of the input |
前瞻后顾
Lookahead and Lookbehind Zero-Length Assertions,它匹配一些字符,但是并不包含匹配模式,只是确定是否匹配,也就是所谓的零宽。
Lookahead: 使用?=,q(?=u)表示q后面必须是u,但匹配结果中不包含u(零宽),同样的有负前瞻,使用?!,比如q(?!u)则表示q后面必须不是u。Lookbehind: 使用?<,(?<q)u表示u前面为q,但匹配结果不包含q(零宽),同样的有负后顾,使用?<!,比如(?<!q)u则表示u前面必须不是q。
下面是一些例子:
abc(?=123) abc123 匹配,abc
123abc 不匹配
abc(?!123) abc123 不匹配
abc444 匹配,abc
(?<abc)123 abc123 匹配,123
xyz123 不匹配
(?<!abc)123 abc123 不匹配
xyz123 匹配,123